- Details

Sound event localization and detection (SELD) is the combined task of identifying the temporal onset and offset of a sound event, tracking the spatial location when active, and further associating a textual label describing the sound event. Our work on SELD was recently published in the reputed journal of selected topics in signal processing (JSTSP). The proposed method was compared with two sound event detection, three direction-of-arrival estimations, and one SELD baselines. The results showed that the proposed method is generic and applicable to any array structures, robust to unseen DOA values, reverberation, and low SNR scenarios. All the datasets used for evaluation and the code has been publicly released to support open research.
- Details
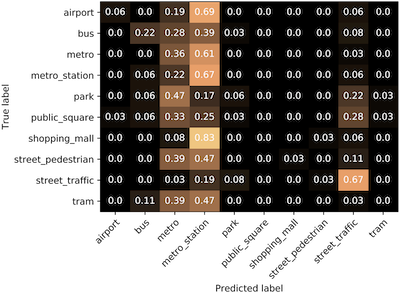
Acoustic scene classification is the task where we try to classify a sound segment (e.g. 30 seconds long) to an acoustic scene, like airport, metro station, office, etc. We get a recording, we give it as an input to our acoustic scene classification method, and the method outputs the acoustic scene where this recording came from. To develop our method, we use a dataset of recordings of a list of acoustic scenes. When the method is ready, we can use it with any other recordings that can be classified to one of the acoustic scenes that our training data had. A known problem is the degradation of such methods when they are used with data recorded with different conditions than the ones used for training.
- Details

A collection of Python utilities for Detection and Classification of Acoustic Scenes and Events research has been released. These utilities were originally created for the DCASE challenge baseline systems (2016 & 2017) and are bundled now into a standalone library to allow their re-usage in other research projects.
- Details

A book edited and authored by members from our research group has been published. The book presents computational methods for extracting the useful information from audio signals, collecting the state of the art in the field of sound event and scene analysis.
- Details

DCASE 2017 Workshop is the second workshop on Detection and Classification of Acoustic Scenes and Events, being organized for the second time in conjunction with the DCASE challenge. The workshop aims to bring together researchers from many different universities and companies with interest in the topic, and provide the opportunity for scientific exchange of ideas and opinions.
- Details

Our research group has published open dataset for sound event detection research, TUT Sound events 2017. The dataset consists of recordings of street acoustic scenes with various levels of traffic and other activity. The scene was selected as representing an environment of interest for detection of sound events related to human activities and hazard situations. Dataset is released in two parts, development dataset and evaluation dataset, and these can be downloaded from Zenodo.
- Details

Our research group has published open dataset for acoustic scene classification research, TUT Acoustic Scenes 2017. The dataset consists of recordings from various acoustic scenes, all having distinct recording locations. For each recording location, 3-5 minute long audio recording was captured. The original recordings were then split into segments with a length of 10 seconds. Dataset is released in two parts, development dataset and evaluation dataset, and these can be downloaded from Zenodo.
- Details

The third DCASE Challenge is organized between 15th March 2017 - 31th July 2017. The challenge is organized by Tampere University of Technology in collaboration with the Carnegie Mellon University, and INRIA, and it is an official IEEE Audio and Acoustic Signal Processing (AASP) challenge. Results of the challenge are presented at the DCASE 2017 Workshop, in which selected peer-reviewed publications on challenge submission are presented.
- Details

sed_eval is an open source Python toolbox which provides a standardized, and transparent way to evaluate sound event detection systems.In addition to this, it provides tools for evaluating acoustic scene classification systems as well as audio tagging.