Computational auditory scene analysis (CASA) aims to separate and recognize mixtures of sound sources present in the auditory scene in a similar manner to humans. Humans can easily segregate and recognize one sound source from an acoustic mixture, such as a certain voice from a busy background including other people talking and music. Machine listening systems try to achieve this perceptual feature using e.g. sound source recognition techniques.
Acoustic scene classification
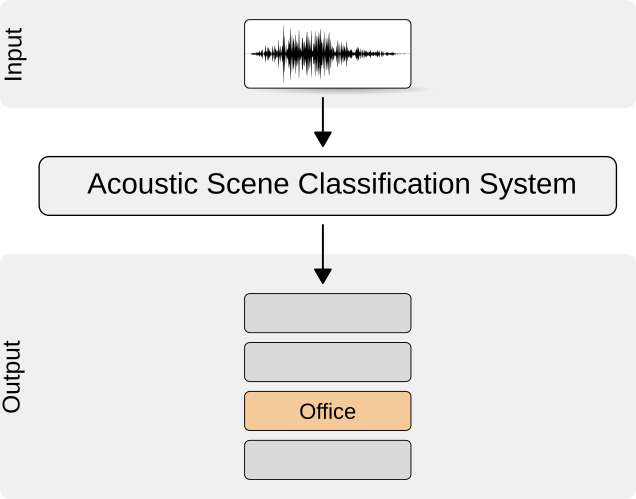 The goal of acoustic scene classification is to classify a test recording into one of the predefined classes that characterize the environment in which it was recorded — for example, "park", "home", "office". This information would enable wearable devices to provide better service to users' needs, e.g., by adjusting the mode of operation based on an acoustic scene or location type. Listening tests conducted in our research group showed that humans are able to recognize everyday acoustic scenes in 70% of cases on average. Current state-of-art automatic scene recognition methods can reach this level of accuracy with a small and well-defined set of classes.
The goal of acoustic scene classification is to classify a test recording into one of the predefined classes that characterize the environment in which it was recorded — for example, "park", "home", "office". This information would enable wearable devices to provide better service to users' needs, e.g., by adjusting the mode of operation based on an acoustic scene or location type. Listening tests conducted in our research group showed that humans are able to recognize everyday acoustic scenes in 70% of cases on average. Current state-of-art automatic scene recognition methods can reach this level of accuracy with a small and well-defined set of classes.
Bibliography
Sound event detection and recognition
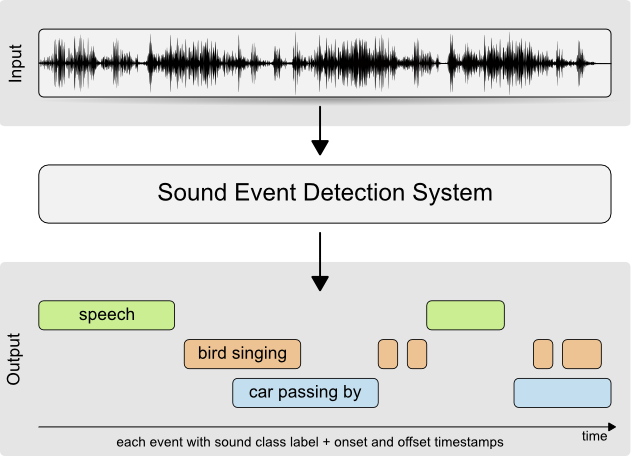 Audio streams, such as broadcast news, meeting recordings, and personal videos contain sounds from a wide variety of sound sources. These streams include audio events related to human presence, such as speech, laughter, or coughing or sounds of animals, objects, nature, or situations. The detection of these events is useful, e.g., for automatic tagging in audio indexing, automatic sound analysis for audio segmentation, or audio context classification.
Audio streams, such as broadcast news, meeting recordings, and personal videos contain sounds from a wide variety of sound sources. These streams include audio events related to human presence, such as speech, laughter, or coughing or sounds of animals, objects, nature, or situations. The detection of these events is useful, e.g., for automatic tagging in audio indexing, automatic sound analysis for audio segmentation, or audio context classification.
An acoustic scene is characterized by the presence of individual sound events. In this respect, we may want to manage a multi-class description of our audio or video files by detecting the categories of sound events that occur in a file. For example, one may want to tag a holiday recording as being on the "beach", playing with the "children" and the "dog", right before the "storm" came. These are different level annotations, and while the beach as a context could be inferred from acoustic events like waves, wind, and water splashing, the audio events "dog barking" or "children" should be explicitly recognized, because such acoustic event may appear in other contexts, too.
Sound event detection and classification aim to process the acoustic signal and convert it into symbolic descriptions of the corresponding sound events present in the acoustic signal. In recent years, we have worked to extend the sound event detection task to a comprehensive set of event-annotated audio material from everyday environments. Most of the everyday auditory scenes are usually complex in sound events, having multiple overlapping sound events active at the same time, and this presents a special challenge to the sound event detection process.
Bibliography
Audio tagging and captioning
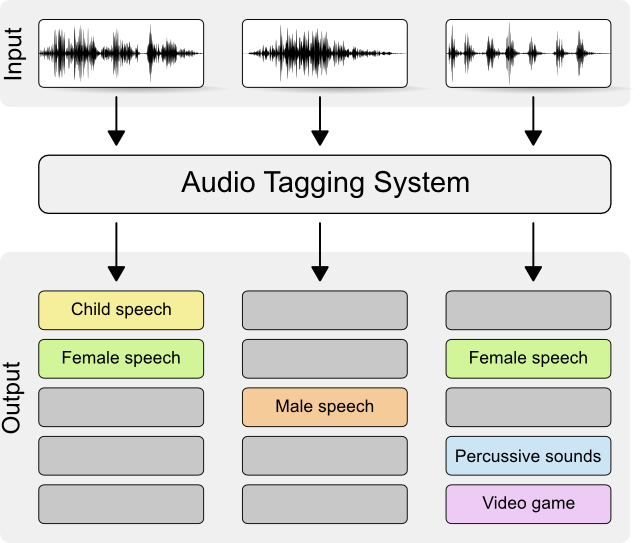 Audio tagging is a sound classification task and refers to identifying the classes that a human can assign to a sound segment. That is, given a sound segment (e.g. a sound file) as an input to an audio tagging system, the output of the latter should be an indication of the classes assigned to the input sound segment. The emphasis on this task is the ability to identify the classes independently of their amount (i.e. large amount of classes to be detected), their frequency of appearing (i.e. classes with an imbalanced and arbitrary frequency of appearance), the length of input audio segment (i.e. arbitrary length of input audio), and the differences of the acoustic conditions/acoustic channels (i.e. recordings from different environments and/or different equipment). In ARG we are working on audio tagging, trying to tackle all the above challenges. At the same time, we constantly working towards gaining more insight and knowledge about the mechanisms involved in human and machine perception and improving the performance of our algorithms and methods for audio tagging.
Audio tagging is a sound classification task and refers to identifying the classes that a human can assign to a sound segment. That is, given a sound segment (e.g. a sound file) as an input to an audio tagging system, the output of the latter should be an indication of the classes assigned to the input sound segment. The emphasis on this task is the ability to identify the classes independently of their amount (i.e. large amount of classes to be detected), their frequency of appearing (i.e. classes with an imbalanced and arbitrary frequency of appearance), the length of input audio segment (i.e. arbitrary length of input audio), and the differences of the acoustic conditions/acoustic channels (i.e. recordings from different environments and/or different equipment). In ARG we are working on audio tagging, trying to tackle all the above challenges. At the same time, we constantly working towards gaining more insight and knowledge about the mechanisms involved in human and machine perception and improving the performance of our algorithms and methods for audio tagging.
 Audio captioning is a recently introduced research direction and it is not to be confused with subtitling. Audio captioning is the task where a system takes a sound segment as an input and outputs a textual description of the content of the audio file. For example, "People talking in a crowded restaurant". It can be considered as an inter-modality translation, where the information represented in one modality (i.e. "sound") is translated to another one (i.e. "text"). It is a complicated task where the method accounted for audio captioning must be able to simultaneously do audio event recognition (to recognize the sound events happening in the sound segment), recognition of spatio-temporal relations and associations (to identify movement and relative location of sound sources), acoustic scene recognition (to identify the acoustic scene, the audio background), and represent all these in a sentence that can actually make sense. In ARG we are happy to have the very first ever publication on this task. Since this task is pretty new, stay tuned for more and exciting results!
Audio captioning is a recently introduced research direction and it is not to be confused with subtitling. Audio captioning is the task where a system takes a sound segment as an input and outputs a textual description of the content of the audio file. For example, "People talking in a crowded restaurant". It can be considered as an inter-modality translation, where the information represented in one modality (i.e. "sound") is translated to another one (i.e. "text"). It is a complicated task where the method accounted for audio captioning must be able to simultaneously do audio event recognition (to recognize the sound events happening in the sound segment), recognition of spatio-temporal relations and associations (to identify movement and relative location of sound sources), acoustic scene recognition (to identify the acoustic scene, the audio background), and represent all these in a sentence that can actually make sense. In ARG we are happy to have the very first ever publication on this task. Since this task is pretty new, stay tuned for more and exciting results!
Bibliography
General audio classification
Audio classification can be applied to any problem where it is useful and meaningful to gain some knowledge about the audio content regarding the particular problem at hand. In addition to audio context and sound event recognition, these kinds of audio classification problems are encountered for example in content-based database retrieval tasks.
Classifying audio into separate pre-determined classes provides useful means for browsing large audio/video databases. As text-based indexing of audio files is very laborious and time-consuming, content-based audio classification has been studied rather widely in the audio signal processing field. Supervised learning methods, both the commonly existing ones as well as some modified ones, are actively being researched in the Audio Research Team, in order to apply such classification and retrieval successfully to realistic-size audio databases. In a general case, the audio content to be classified need not be limited to any specific type of audio, such as speech or music, as long as the training dataset used for training the used classifier(s) is representative enough to cover all the specified class types.