Publications
SELDnet: Sound event localization and detection of overlapping sources using convolutional recurrent neural networks
In this paper, we propose a convolutional recurrent neural network for joint sound event localization and detec tion (SELD) of multiple overlapping sound events in three-dimensional (3D) space. The proposed network takes a sequence of consecutive spectrogram time-frames as input and maps it to two outputs in parallel. As the first output, the sound event detection (SED) is performed as a multi-label classification task on each time-frame producing temporal activity for all the sound event classes. As the second output, localization is performed by estimating the 3D Cartesian coordinates of the direction-of-
arrival (DOA) for each sound event class using multi-output regression. The proposed method is able to associate multiple DOAs with respective sound event labels and further track this association with respect to time. The proposed method uses separately the phase and magnitude component of the spectrogram calculated on each audio channel as the feature, thereby avoiding any method- and array-specific feature extraction. The method is evaluated on five Ambisonic and two circular array format datasets with different overlapping sound events in anechoic, reverberant and real-life scenarios. The proposed method is compared with two SED, three DOA estimation, and one SELD baselines. The results show that the proposed method is generic and applicable to any array structures, robust to unseen DOA values, reverberation, and low SNR scenarios. The proposed method achieved a consistently higher recall of the estimated number of DOAs across datasets in comparison to the best baseline. Additionally, this recall was observed to be significantly better than the best baseline method for a higher number of overlapping sound events.
MaD TwinNet: Masker-Denoiser Architecture with Twin Networks for Monaural Sound Source Separation
Monaural singing voice separation task focuses on the prediction of the singing voice from a single channel music mixture signal. Current state of the art (SOTA) results in monaural singing voice separation are obtained with deep learning based methods. In this work we present a novel deep learning based method that learns long-term temporal patterns and structures of a musical piece. We build upon the recently proposed Masker-Denoiser (MaD) architecture and we enhance it with the Twin Networks, a technique to regularize a recurrent generative network using a backward running copy of the network. We evaluate our method using the Demixing Secret Dataset and we obtain an increment to signal-to-distortion ratio (SDR) of 0.37 dB and to signal-to-interference ratio (SIR) of 0.23 dB, compared to previous SOTA results.
GitHub Publication Online DemoDCASE2017 Task 3: Real-life sound event detection winning method
Sound event detection (SED) is the task of recognizing the sound events and their respective temporal start and end time in a recording. Sound events in real life do not always occur in isolation but tend to considerably overlap with each other. Recognizing such overlapping sound events is referred as polyphonic SED. Performing polyphonic SED using mono-channel audio is a challenging task. These overlapping sound events can potentially be recognized better with multichannel audio. The proposed MSEDnet intends to do polyphonic SED using multichannel audio. MSEDnet was first proposed in 'Sound event detection using spatial features and convolutional recurrent neural network'. It recently won the DCASE 2017 real-life sound event detection. We are releasing a simple vanilla code without many frills here.
GitHub Publication DCASE2017Reference systems
DCASE2018 Baseline system for acoustic scene classification
This is the baseline system for the Detection and Classification of Acoustic Scenes and Events 2018 (DCASE2018) challenge's acoustic scene classification task.
GitHubDCASE2017 Baseline system
Python implementation
This is the baseline system for the Detection and Classification of Acoustic Scenes and Events 2017 (DCASE2017) challenge tasks. The baseline system is intended to lower the hurdle to participate the DCASE challenges. It provides an entry-level approach which is simple but relatively close to the state of the art systems to give reasonable performance for all the tasks. High-end performance is left for the challenge participants to find. In the baseline, one single low-level approach is shared across the tasks by application-specific extensions. The main idea of this is to show the parallelism in the tasks settings, and show how easily one can jump between tasks during the system development.

DCASE2016 Baseline system
This is the baseline system for the Detection and Classification of Acoustic Scenes and Events 2016 (DCASE2017) challenge tasks. It is proveded in two parallel implementations (Python and Matlab) to lower the hurdle from switching from Matlab to Python.
GitHub (Python) GitHub (Matlab)Toolboxes and libraries
dcase_util — utilities for DCASE related research
A collection of Python utilities for Detection and Classification of Acoustic Scenes and Events.
GitHub Documentation
sed_eval — toolbox for sound event detection system evaluation
sed_eval is an open source Python toolbox which provides a standardized, and transparent way to evaluate sound event detection systems. In addition to this, it provides tools for evaluating acoustic scene classification systems, as the fields are closely related.
GitHub Documentation
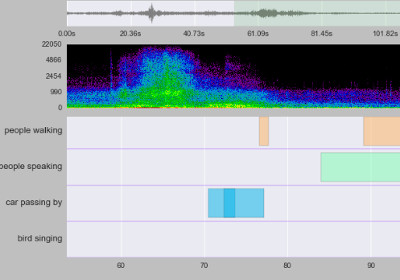
sed_vis — visualizing sound event detection output
sed_vis is an open source Python toolbox for visualizing the annotations and system outputs of sound event detection systems. It provides an event roll-type of visualizer to show annotation and/or system output along with the audio signal. The audio signal can be played and indicator bar can be used to follow the sound events.
GitHub