
Source separation means the tasks of estimating the signal produced by an individual sound source from a mixture signal consisting of several sources. This is a very fundamental problem in many audio signal processing tasks since analysis and processing of isolated sources can be done with much better accuracy than the processing of mixtures of sounds. Human listeners will also benefit from source separation in many applications, for example in hearing aids.
Singing voice and music separation
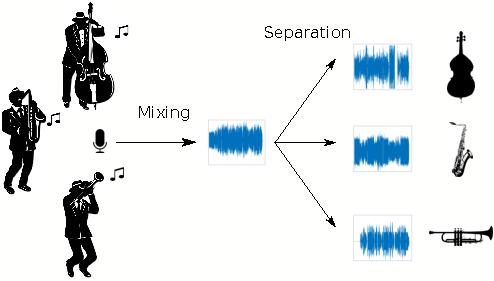 The separation of instrumental tracks from a music song is an important topic in music signal processing since it serves as a preprocessing step for higher-level applications. Indeed, many musical processings perform better when applied to individual tracks rather than directly on the mixture. For instance, extracting the singing voice from the musical accompaniment is helpful for lyrics transcription and karaoke. Separating pitched and percussive sounds (such as drums) is useful for rhythm analysis and time-stretching applications. The group has pioneered several kinds of research on music source separation, notably through statistical and nonnegative matrix factorization models, as well as with modern deep learning architectures.
The separation of instrumental tracks from a music song is an important topic in music signal processing since it serves as a preprocessing step for higher-level applications. Indeed, many musical processings perform better when applied to individual tracks rather than directly on the mixture. For instance, extracting the singing voice from the musical accompaniment is helpful for lyrics transcription and karaoke. Separating pitched and percussive sounds (such as drums) is useful for rhythm analysis and time-stretching applications. The group has pioneered several kinds of research on music source separation, notably through statistical and nonnegative matrix factorization models, as well as with modern deep learning architectures.
Bibliography
Spatial sound source separation
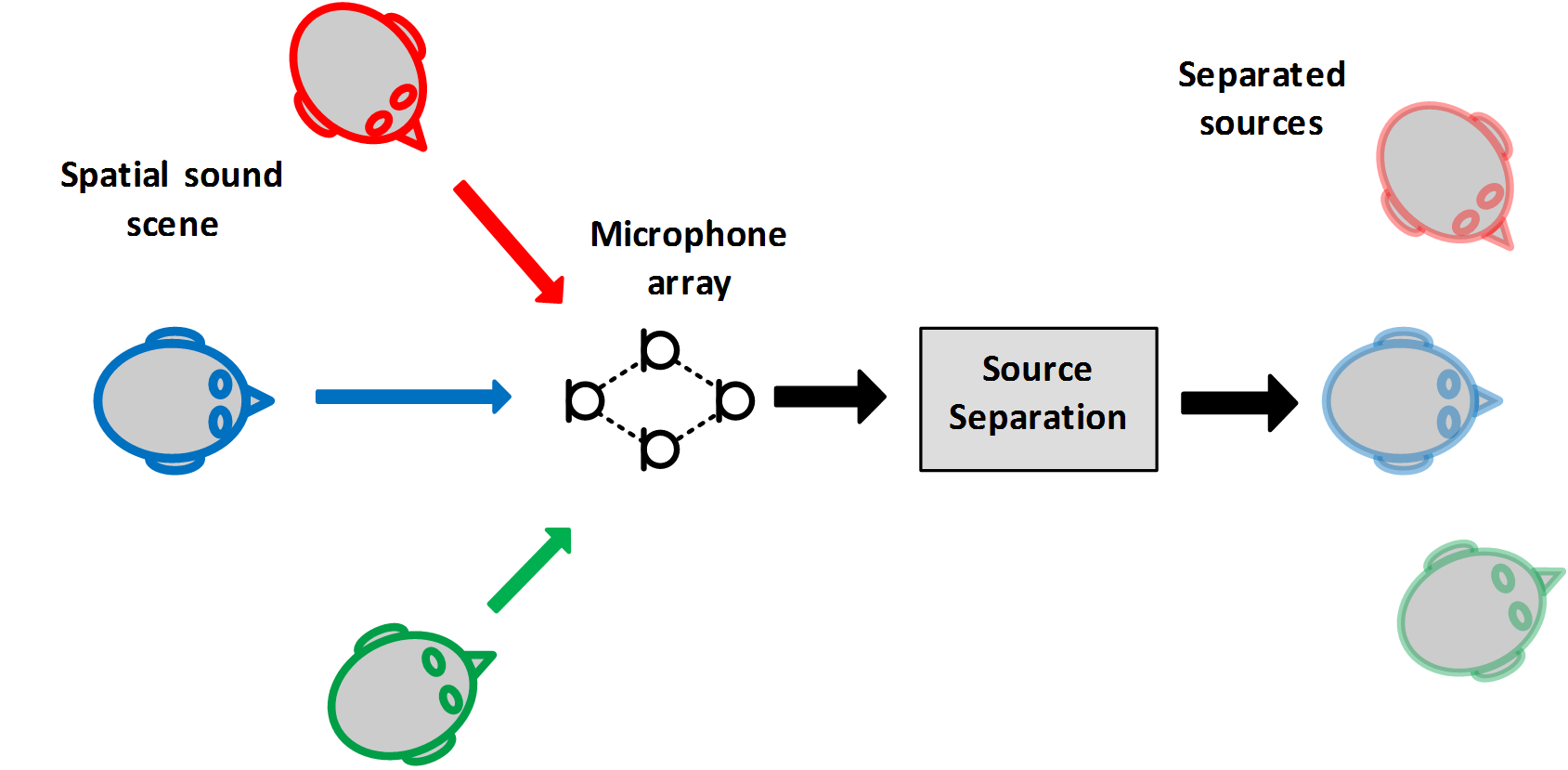 Human hearing can separate sounds based on their perceived direction and the same principles are utilized in spatial sound source separation to enhance and separate sounds coming from a certain direction or location. Spatial sound source separation utilizes directional features obtained by using multiple microphones (microphone array) to capture the sound scene. The separation methods can be divided into separation mask estimation and direct source signal estimation conditioned to a certain direction or spatial location. Often the spatial sound source separation requires solving the problem of source direction of arrival estimation and source trajectory estimation jointly or as a preprocessing step. For further details please refer to spatial audio research pages.
Human hearing can separate sounds based on their perceived direction and the same principles are utilized in spatial sound source separation to enhance and separate sounds coming from a certain direction or location. Spatial sound source separation utilizes directional features obtained by using multiple microphones (microphone array) to capture the sound scene. The separation methods can be divided into separation mask estimation and direct source signal estimation conditioned to a certain direction or spatial location. Often the spatial sound source separation requires solving the problem of source direction of arrival estimation and source trajectory estimation jointly or as a preprocessing step. For further details please refer to spatial audio research pages.
Object-based coding of spatial audio
Separation of sound objects from spatial audio mixtures allows encoding the source/object signal and its spatial parameters (mixing) separately as side information. Representing spatial audio mixture as objects with interpretable direction is efficient from an encoding perspective and object-based representations allow modification of the observed sound scene during the spatial synthesis. Previously the group has conducted pioneering research on object-based multichannel audio upmixing.
Speech enhancement and separation
One specific task in source separation is the enhancement of the target speaker's voice from background noise or interfering voices. The applications of speech separation range from preprocessing for automatic speech recognition (ASR) all way to provide ease of everyday communication for hearing-impaired listeners. Machine and deep learning are used for training models to learn to distinct and separate target speech over the interfering sounds preserving only the signal components corresponding to the target speech. The goal of speech enhancement, in general, is improving the intelligibility of speech either for humans or machines to listen for. The success of speech enhancement is often measured and predicted using objective criteria, while our groups' work also involves listening tests in determining the actual intelligibility of separated speech with human listeners.
Bibliography