Proposed method
Our proposed method for HPSS is based on two of
out previous works. One is the
MaD TwinNet and the other is the
Phase Unwrapping (PU)
phase recovery algorithm
For convenience, below you can find a brief introduction to the above mention methods. It has to be
noted that we offer code for both of our methods and pre-trained weights (where applicable), in order to
help reproducibility.
So, feel free and use our methods, visit, star, and clone out GitHub repositories, and enjoy separating
sources!
Below you can see an illustration of our proposed method for
HPSS.
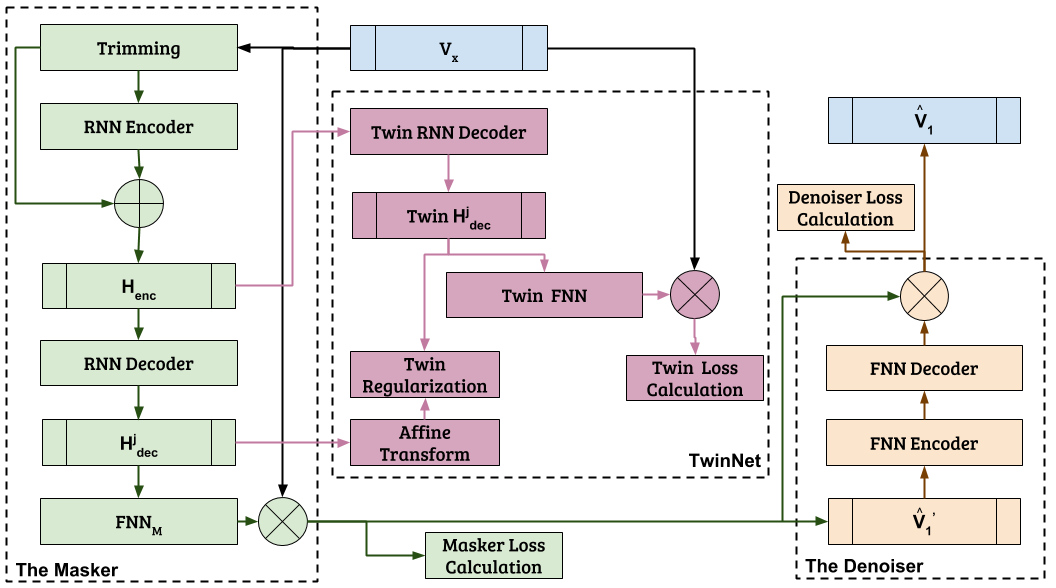
MaD TwinNet
MaD TwinNet is based on the Masker-Denoiser architecture, augmented with the Twin Network. Thus,
the "MaD" is from the "Masker-Denoiser" and TwinNet from the Twin Network. The role of MaD TwinNet
in this work is to perform the separation of the percussive and the harmonic components. For a general
presentation of the MaD TwinNet, you can check at
the corresponding paper
and demo.
The Masker is the first component of MaD TwinNet and accepts as an input the magnitude spectrogram of the
mixture. Then, the Masker predicts and applies a time-frequency mask to its input and outputs a first estimate
of the magnitude spectrogram of the percussive components. This estimate of the percussive components is
then given as an input to the Denoiser.
The Denoiser predicts and applies a time-frequency denoising filter to the estimated percussive
components. This filter aims at removing interferences, artifacts, and (in general) any other noise
introduced by the separation process from the Masker.
After the application of the denoising filter by the Denoiser, the now cleaned estimated of the
magnitude spectrogram of the percussive components can be used to estimate the harmonic components.
This result in having separated the percussive and harmonic components.
The estimated harmonic components are given as an input to the PU algorithm to enhance them more, by
applying improved phase recovery techniques.
Illustration of the MaD TwinNet for HPSS
Phase recovery
The most common approach when separating music signals by employing magnitude spectrogram is to use the phase
of the mixture. This approach is equivalent to assuming that each time-frequency bin of the short-time Fourier
transform (STFT) contains information for only
one source. In a realistic scenario, such as the harmonic/percussive case, this assumption does no longer hold
since the sources are strongly overlapping in time and frequency.
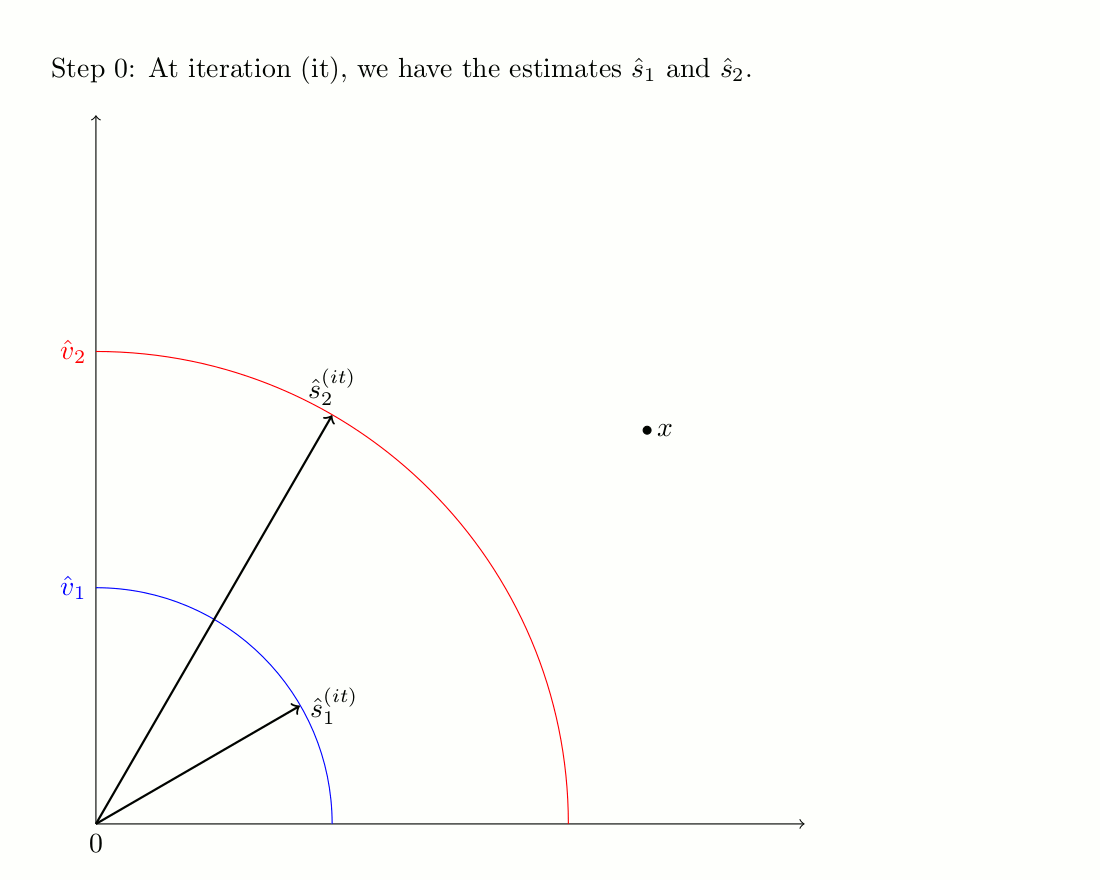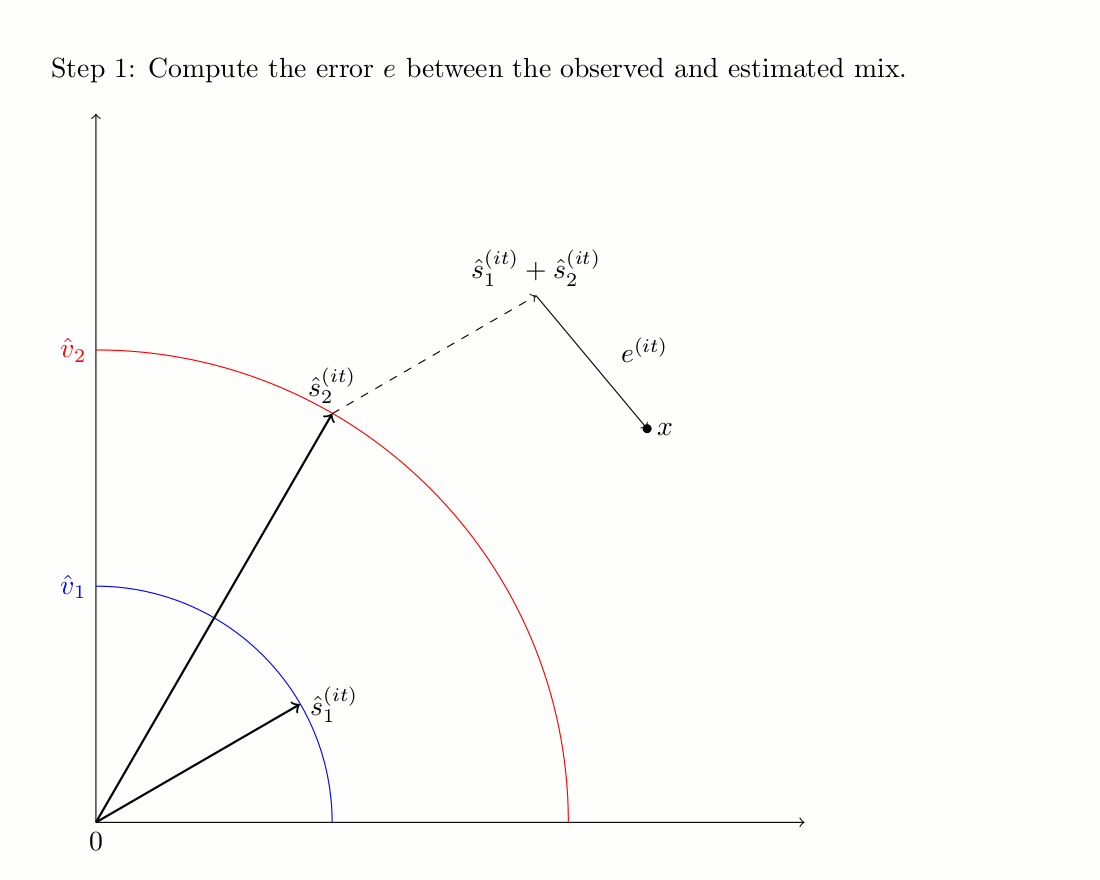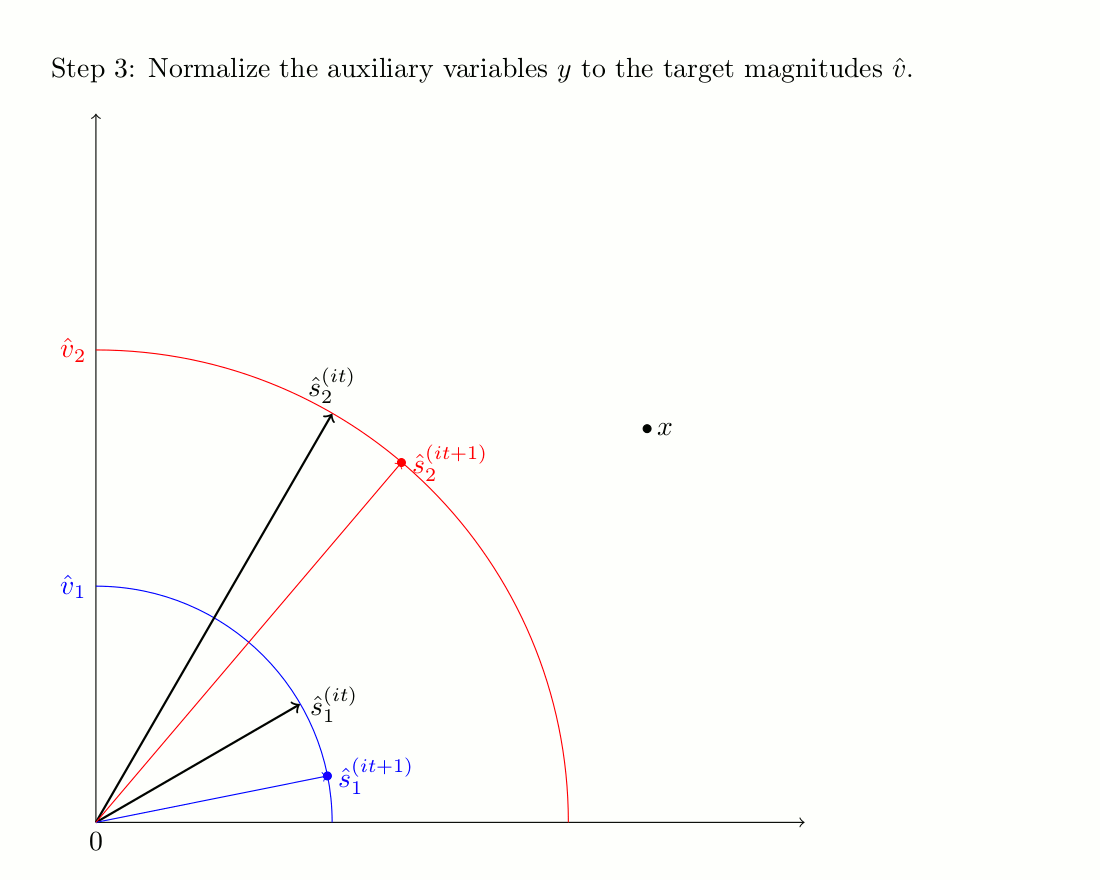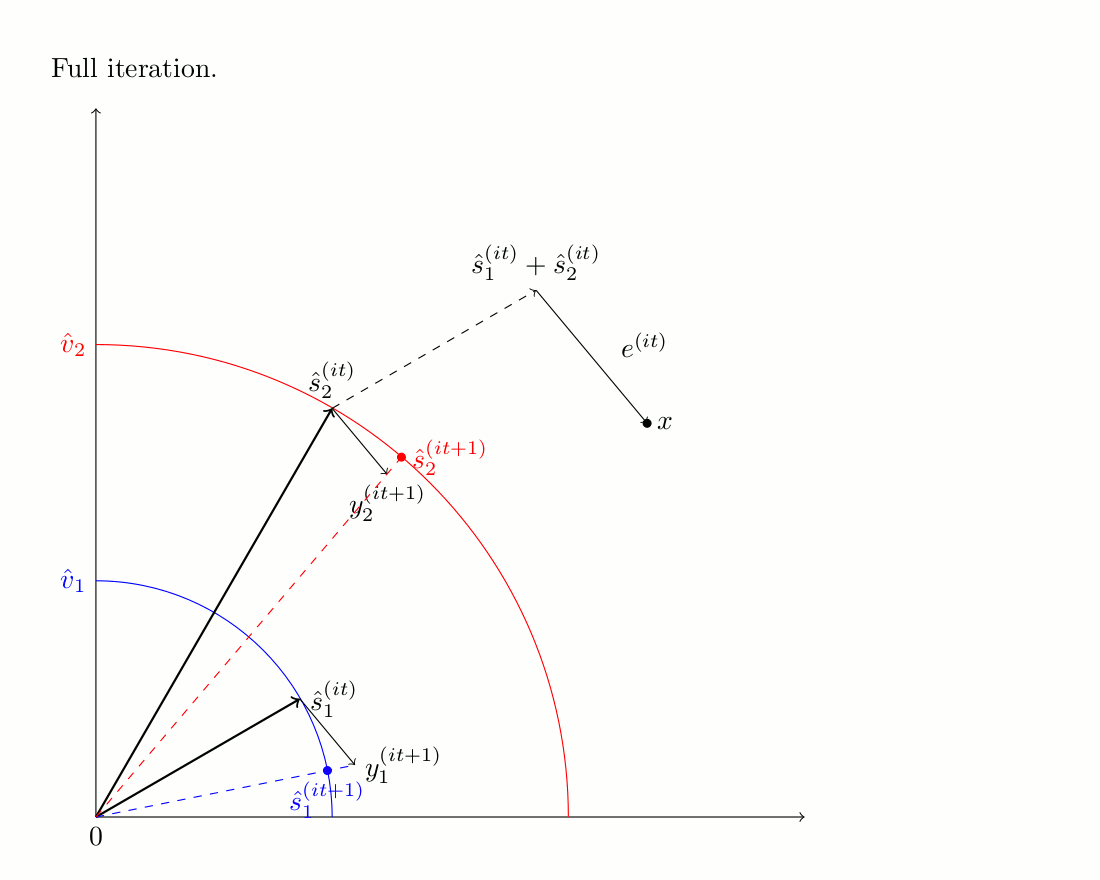
The PU algorithm consists in predicting the phase of the harmonic source by using a sinusoidal model.
Then, from this initial estimate, an iterative procedure is applied to minimize the mixing error and yield the
final sources estimates. We applied the PU algorithm on the predictions of the harmonic components, in order
to reduce the interferences from the percussive sources.
The iterative process is illustrated in the image bellow, and more details can be found on the
corresponding website.
The iterative scheme of PU-Iter when there are 2 complex numbers to be estimated.
 .
Don't hesitate to
contact us!
.
Don't hesitate to
contact us!